eBP... Quoi?
L'idée est née avec BPF ( Berkeley Package Filter ), apparu pour la première fois en 1993 puis intégré au kernel en 1997 avec la version 2.1.75. BPF était une petite machine virtuelle à l'intérieur du kernel où on pouvait y injecter des instructions pour faire des règles de filtrage réseau.
L'usage de base était donc uniquement de filtrer des paquets réseau directement depuis le kernelspace plutôt que tout réclamer puis filtrer depuis le userspace, d'où le nom "Packet Filter". Tcpdump est basé dessus depuis longtemps.
Une première évolution est arrivée en 2012 avec la gestion des appels systèmes, puis en 2013 sort enfin eBPF, ou Extended Berkeley Package Filter , qui est maintenant amélioré à chaque nouvelle release Linux.
Avec eBPF arrive une extension des capacités de la VM et surtout une vraie interface avec celle-ci. On va pouvoir y injecter du code C à exécuter. Mais attention, il ne s'agit pas d'aller y faire n'importe quoi, il y a un vérifieur qui va contrôler le programme injecté : pas de boucles infinies, pas de pointeurs non controlés, pas d'allocation dynamique... eBPF fournit aussi beaucoup de fonctions pour notre programme. Vous l'aurez compris, le programme injecté sera très bordé. De plus, étant dans une VM, le programme est exécuté en sandbox, avec un nombre d'instructions et de ressources limitées, et compilé en Just In Time . La possibilité de faire crasher le kernel est ainsi éliminée.
Ce n'est donc plus seulement un outil pour le filtrage réseau, mais un réel outil de tracing à l'intérieur même du kernel. On pourra tracer les appels systèmes (en utilisant les kprobes ou tracepoints qui existent déjà depuis bien longtemps), tracer les langages qui fournissent leurs propres probes (comme nous le verrons un peu plus loin), et plus généralement avoir une visibilité sur à peu près tout ce qui passe par le kernel… La seule limite est l'imagination.
Utilisation
Il y a plusieurs manières d'interagir avec eBPF, en C via notamment l'utilisation de l'appel système bpf , ou en utilisant un "frontend" qui va nous fournir une interface dans un langage de plus haut niveau, ou encore l'outil en ligne de commande bpftrace .
Bpftrace est un outil en ligne de commande principalement fait pour récupérer des informations et debbuger à chaud.
Nous allons surtout nous intéresser à BCC, un frontend python (mais aussi lua, golang…) maintenu par le projet open source IO Visor de la Linux Foundation .
BCC est supporté intégralement depuis la version 4.9 du kernel (décembre 2016), c'est un framework relativement récent et encore en développement. Il se trouve dans les paquets Debian sous sa version 0.8.0 (dans Buster).
Le projet fournit beaucoup de scripts et tools généralistes prêts à l'emploi pour diverses tâches (paquet debian bpfcc-tools ), surveiller l'appel à certains syscalls, monitorer l'utilisation du réseau, détecter les fuites mémoire, etc. Ces outils sont intégrés par défaut sur les (fort nombreux) serveurs de chez Netflix et Facebook, entre autres…
Voici la liste officielle:
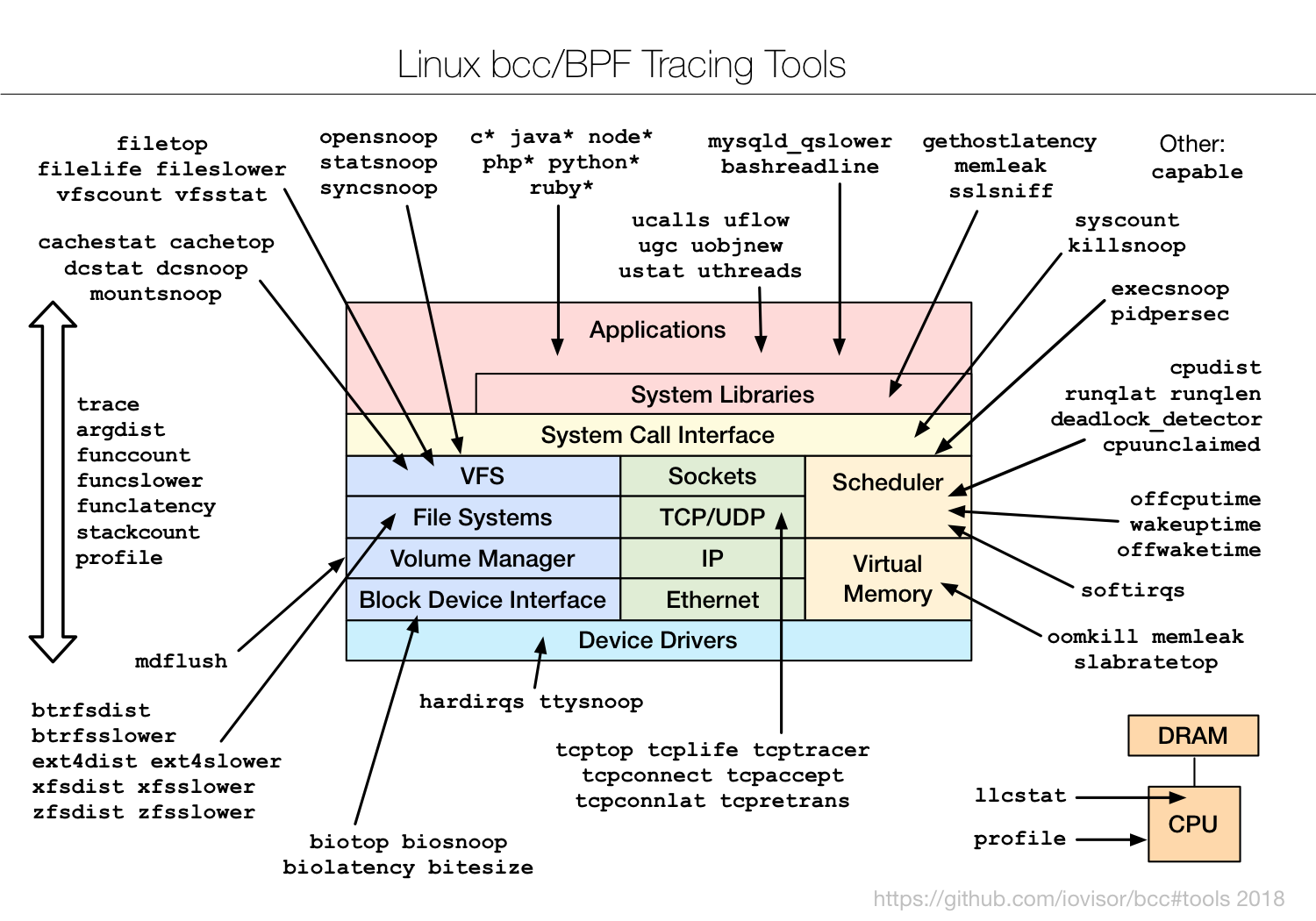
Vous trouverez des informations sur chacun d'entre eux sur le github du projet dans le dossier "tools".
Intéressons-nous maintenant à une partie plus excitante : l'écriture d'outils avec BCC. Sous Debian, nous avons besoin des paquets bpfcc-tools et bpfcc-python3 . Voici un exemple simple :
#!/usr/bin/env python import os from bcc import BPF # Le programme C que l'on va injecter dans le kernel program=''' int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello World\\n"); return 0; } ''' # On lance notre programme b = BPF(text = program) while 1: # Récuperation des informations envoyées par le kernel (task, pid, cpu, flags, ts, msg) = b.trace_fields() # Formatage des infos print("PID = %u\nPROGRAM = %s\nMESSAGE = %s\n" % (pid, task, msg))
Ce programme injecte un code C dans le kernel, qui va nous renvoyer un message "Hello World" à chaque fois qu'un processus est créé. Cela se décompose en trois étapes : la création du programme C, son injection dans eBPF et la récupération et traitement des informations en python.
Dans ce programme d'exemple, nous utilisons la technique simple du fichier /sys/kernel/debug/tracing/trace_pipe . eBPF écrit dedans ce qu'on lui a demandé avec la fonction bpf_trace_printk , et nous récupérons son contenu avec la fonction trace_fields dans notre code python. Cette méthode est bien pour un programme simple, mais n'est pas recommandée.
Il existe deux autres méthodes bien plus efficaces : les structures MAPS et le tampon PERF .
Les structures MAPS sont un type de données propres à eBPF, un simple tableau clés/valeurs permettant de stocker des données, qui seront gardées à chaque nouvelle exécution du programme. On pourra ainsi stocker des informations persistantes comme des statistiques sur le nombre d'appels systèmes, des compteurs, etc. Le tampon PERF est une technique qui permet de stocker des informations dans une structure C classique, puis de la récupérer et la parser dans une structure python et ainsi accéder à tous ses champs directement dans notre script. Les structures C disparaitront à chaque fin d'exécution du programme eBPF. On comprend donc qu'il faudra utiliser les deux techniques afin de renvoyer des structures avec les informations et de stocker nos compteurs ou statistiques dans des MAPS.
Un programme eBPF va surveiller des "tracepoints", il en existe quatre types : tracepoint , kprobe , usdt et uprobe . Les kprobe et uprobe sont des tracepoints "dynamiques", c'est-à-dire qu'ils vont récupérer des informations à chaud sur les programmes utilisateurs pour les uprobe et kernel pour les kprobe . Ils ne nécessitent pas la recompilation du programme, mais sont susceptibles de changer en fonction des versions du kernel. Quant aux tracepoint et usdt , ce sont des tracepoints "statiques", ils sont définis directement dans le code source du programme, utilisateur pour usdt et kernel pour tracepoint . La recompilation du programme est donc nécessaire.
Différents tracepoints sont donc exposés par les programmes et nous nous branchons dessus pour récupérer leurs évènements grâce à eBPF.
Nous venons de voir que les tracepoints statiques appartiennent aux programmes, ils sont donc accessibles par eBPF via le PID du processus de ces programmes. Quelque chose devrait commencer à vous venir en tête…
Si nous regardons la liste des processus sur un serveur, qui contient des programmes qui tournent et des conteneurs, nous voyons aussi les processus lancés dans ces fameux conteneurs.
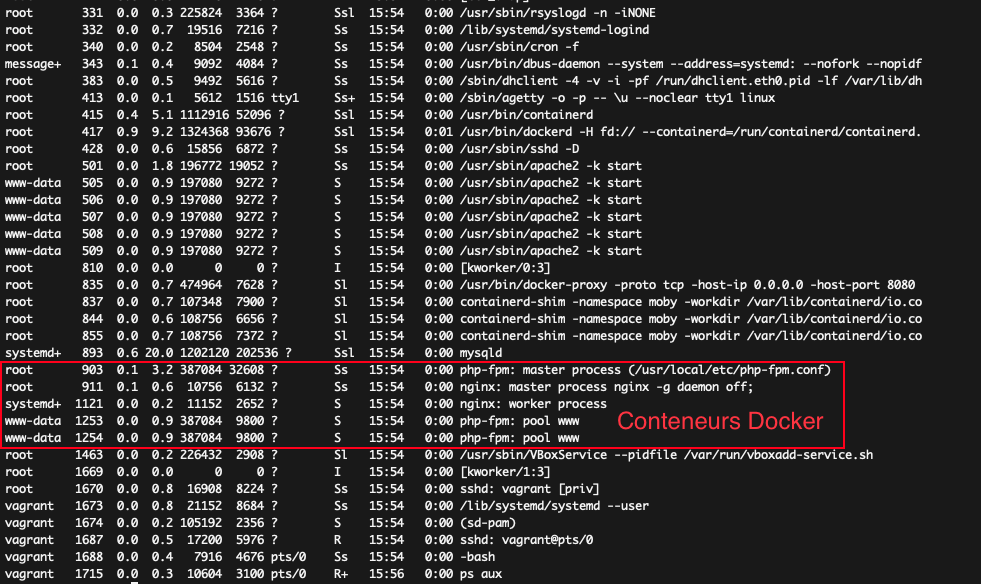
Pour ceux que ça étonne, un petit rappel sur ce qu'est un conteneur est nécessaire.
Cela veut donc dire qu'avec les tracepoints, nous allons pouvoir instrumenter n'importe quel programme compatible, qu'il soit dans un conteneur ou non.
Dans l'article de la semaine prochaine, nous verrons plus en détail le cas concret d'un outil basé sur BCC avec un projet que nous avons réalisé permettant de tracer et observer le comportement d'une application PHP.
Conclusion
Nous venons de découvrir les possibilités offertes par eBPF et la façon dont on peut l'utiliser pour instrumenter les évènements d'un langage ou du kernel, en gardant une performance exceptionnelle étant donné que le code est exécuté directement dans le kernelspace et que les échanges kernelspace/userspace sont limités le plus possible. Cela donne des outils performants, et utilisables en boite noire dans un environnement réel, comme une production, pour comprendre le comportement de son application et ainsi détecter des fautes de programmation, des problèmes de librairies ou d'API tierces...
eBPF est une technologie dont l'idée et le besoin sont anciens, mais la réalisation moderne est très récente. Tout reste à faire et il y a encore peu d'outils basés dessus. On peut tout de même citer non exhaustivement
On sait également que Facebook l'utilise, Twitter aussi, ainsi que Netflix. Aussi, nous pouvons supposer sans trop prendre de risque que les gros acteurs du Cloud de type Google/Amazon, pour ne pas les citer, travaillent déjà dessus étant donné l'énorme potentiel d'eBPF. D'ailleurs l'initiateur du projet BCC et expert eBPF est Brendan Gregg , ingénieur chez Netflix, auteur et spécialiste en performance système. Son dernier livre, BPF performance tools , sortira en novembre et devrait poser les bases d'eBPF.