Lors du développement d'une application PHP, vous avez déjà dû rencontrer une erreur d'allocation mémoire ou un traitement interrompu par faute d'un timeout . Vous avez alors cherché le paramètre limitant et avez mis une valeur déraisonnable. Ne mentez pas, vous l'avez tous fait.
Mais pourquoi y a-t-il tant de limites sur notre chemin, est-ce pour notre bien ? Et si oui, pourquoi et comment choisir ces valeurs ?
Nous allons parler plus particulièrement de :
Ces paramètres ont la particularité de contrôler l'accès aux ressources les plus stratégiques d'un serveur : le CPU et la RAM. Le grand sujet non abordé - et non traité par PHP - sera les I/Os. Nous ne parlerons pas des autres limites plus fonctionnelles telles que la taille des uploads, le nombre maximum d'arguments de la query string , etc.
Le contexte est primordial
Dans le cas de PHP, le contexte principal est appelé le SAPI. Il suffit de distinguer deux cas :
Le SAPI CLI correspond à l'invocation de PHP en ligne de commande. Ceci inclut un appel direct dans un shell interactif, ou indirect à travers un outil de déploiement (Capistrano, Ansible, etc.) ou à travers un automate prévisible comme cron . Vous pouvez considérer que l'invocation des programmes dans ce contexte est sous votre contrôle : vous avez les moyens de décider exactement quand et à quel rythme vous invoquez des commandes PHP (même si ça peut facilement déraper, surtout avec cron ).
Les autres SAPI : CGI, Apache, FPM servent à répondre aux requêtes de vos utilisateurs. Ceci est hors de votre contrôle, vous ne savez pas quand et à quel rythme les sollicitations vont avoir lieu. Ces sollicitations n'ont potentiellement pas de limites (pensez DDoS), mais votre serveur si.
Vous pouvez déjà en déduire que choisir ces limites ne sera pas le même exercice pour les deux classes de SAPI .
Par contre, cela semble évident mais écrivons-le noir sur blanc : la somme des programmes PHP s'exécutant simultanément quel que soit leur SAPI ne peut pas consommer plus que la quantité de CPU et de RAM que vous offre votre serveur.
Les problèmes de RAM
Ne pas utiliser plus de mémoire que disponible semble une bonne idée, mais en fait que risque-t-on ? Et de quelle mémoire parle-t-on ?
Sur un OS moderne, un programme alloue de la mémoire dans un stock appelé mémoire virtuelle . Cet espace a une capacité égale à environ la somme de la RAM physique du serveur et de celle du swap (sur disque) - le BIOS, le kernel et les services essentiels ayant une consommation minimale non négociable. Sur une Debian 10 avec un LAMP (bien) installé, au repos, vous constaterez que c'est très faible - de l'ordre de 100 MB. C'est pour cela qu'on néglige souvent ce coût, mais vérifiez cette hypothèse chez vous avant de continuer.
Le swap ne sert pas aux allocations immédiates car il est très lent, il sert à déplacer des espaces mémoire alloués mais peu ou pas utilisés, libérant ainsi de la mémoire physique à bon escient. Sur un serveur bien dimensionné et configuré, vous verrez le swap se stabiliser au bout de 1 à 24h : s'il ne bouge pas, il a parfaitement fait son boulot car 1/ il maximise la disponibilité de la RAM physique rapide pour vos programmes interactifs et 2/ il n'a qu'une activité marginale n'affectant pas vos performances.
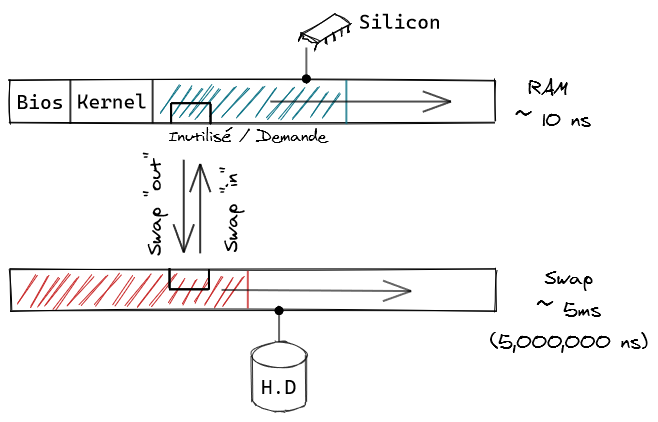
Tout ceci étant pris en compte, vos programmes interactifs peuvent souvent compter sur la disponibilité à peu près entière de la RAM physique (si vous n'avez pas installé trop de services inutiles ou mal configuré certains d'entre eux). C'est pour cela qu'on va utiliser cette capacité pour nos dimensionnements, et ne pas prendre en compte le swap.
Enfin que va-t-il se passer si la RAM vient à manquer pour vos programmes interactifs ?
Echec d'allocation : c'est le mieux qui puisse vous arriver. Le programme est notifié qu'une allocation mémoire a échoué et peut décider de son sort. Par contre il est très courant que les programmeurs testent mal ou peu leurs allocations mémoires, croyant qu'elles ne peuvent jamais échouer. Ces situations créent donc aussi pas mal de crashes (par ex. un
malloc()ounewqui renvoient un pointeur NULL joyeusement déréférencé à la ligne suivante). Vous trouverez dans votre dmesg des événements de ce type :[642582.794298] php7-cgi[3968]: segfault at 73f2f10 ip 00000000006a4d46 sp 00007ffc914d2260 error 4 in php7-cgi[400000+6fb000]- Transfert de swap : le kernel essaye de sauver la mise en déplaçant des morceaux de mémoire virtuelle de/vers le disque. Ca peut marcher de façon très ponctuelle, mais si la sur-sollicitation en RAM est chronique ou s'accélère (un coup de pub sur votre site !) ça finit en fameux swap hell . Et là, les performances de votre serveur tendent vers celles d'un Minitel sous antidépresseurs, il vous reste à choisir entre un hard reboot qui dure 1min ou un long coma qui peut durer des heures (ce qui vous donne un bon indice sur le choix à faire).
Les problèmes de CPU
En première approche vous vous direz : prévoyons un processus par coeur CPU, et on ne devrait jamais déborder tout en utilisant bien le parallélisme que nous offre un CPU multi-coeur. Ceux qui ont essayé ont dû s'en rendre compte : vous aurez une sous-utilisation du CPU très nette et des temps de réponse aléatoires et peu flatteurs.
La raison est que chaque processus n'est pas réduit à un simple calcul qui ne ferait que solliciter le CPU. Quand une application PHP répond à une requête PHP, elle va bien entendu utiliser le CPU pour compiler du code et l'exécuter. Mais elle va aussi attendre que beaucoup d'opérations se réalisent hors du processus et qui ne consomment pas forcément du CPU : lire des fichiers et communiquer avec un service distant comme un serveur SQL. La meilleure illustration de ce principe s'obtient avec la commande time (qui est soit un builtin bash, soit la commande issue du package du même nom) :
$ time curl -s https://bearstech.com/ >/dev/null real 0m0.210s user 0m0.016s sys 0m0.012s Ici la commande curl a téléchargé un code source HTML, elle a utilisé 38ms de temps CPU dont 16ms dans le programme lui-même (' user ') et 12ms dans le kernel (ouverture de fichier, de socket, etc.). Le temps écoulé au chrono est de 210ms, donc ce processus n'a utilisé le CPU que 38ms sur 210ms (18%). Ces 172ms de "non-CPU" n'ont probablement utilisé aucune ressource de la machine (pour l'affirmer c'est plus complexe), il s'agit de simple "attente". Bien entendu d'autres ressources ont été consommées sur d'autres équipements (liens réseaux, switches, serveur HTTP, serveur SQL, etc.) mais vous pourrez les analyser séparément.
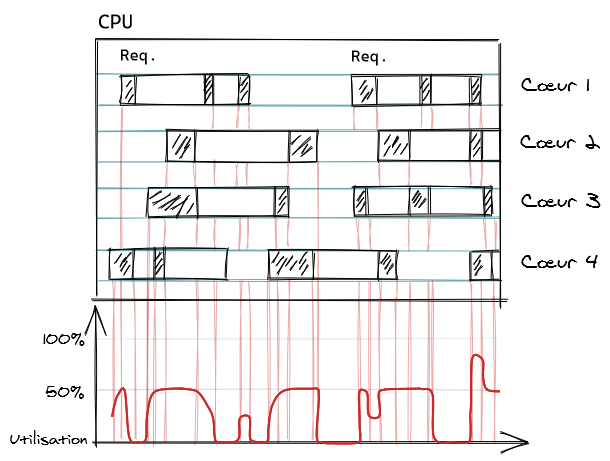
En pratique vous constaterez qu'une application PHP utilise peu de CPU et attend beaucoup - si vous voyez le contraire c'est qu'elle est probablement mal conçue, optimisez-là à l'aide d'un profileur . Par défaut, seul le SAPI FPM vous permet de logger ces mesures d'utilisation du CPU et du temps, via la directive %C de son access.format . Pour les autres SAPIs, c'est contournable, voyez par exemple une solution maison comme phptop .
Autre constat de la vraie vie : un site au trafic même modeste aura très probablement besoin de pouvoir traiter simultanément au moins une dizaine de requêtes simultanées, c'est même souvent un minimum. Or, nous n'avons pas tous le budget pour avoir des serveurs (même virtuels) à 12, 16 coeurs ou plus.
Vous l'aurez compris : il va vous falloir plus de processus PHP simultanés que de coeurs. Mais combien ? La théorie vous dit que cela dépend du ratio calcul/attente de votre application, et notre expérience nous montre que ce ratio est très variable. Empiriquement, nous déployons avec un facteur 4x (4 coeurs : 16 processus simultanés max), puis nous ajustons avec l'observation.
Même question que pour la RAM, que va-t-il se passer si on utilise plus de CPU que l'on en a ?
- Les processus vont ralentir : l'ordonnanceur va attribuer le CPU à tour de rôle aux processus en demande. Par exemple, si au même instant vous avez deux processus réclamant un CPU, ils n'auront que la moitié du CPU en moyenne. Et s'ils traitent une requête en 100 ms CPU quand ils ont le CPU rien que pour eux, ils consommeront toujours 100 ms CPU mais au chronomètre cela représentera 200 ms. Cette demande de CPU se mesure, elle s'appelle la charge chez Unix. Si vous observez une charge de 4 ( la charge n'a pas d'unité ) et que vous avez 2 coeurs, vous pouvez conclure que vos processus sont deux fois plus lents qu'en régime nominal (pour leur portion strictement calculatoire).
- Les files d'attentes vont s'allonger : si votre serveur n'a pas les ressources nécessaires pour traiter en temps "normal" son travail usuel, il va accumuler du retard. Mais si les requêtes entrantes qui provoquent ce sur-régime arrivent avec un débit constant (ou croissant), ces files d'attentes ne peuvent que s'allonger, jusqu'à générer des services ou des utilisateurs excédés qui vont interrompre la requête : timeout !
Résister, c'est refuser
Pour ne pas rencontrer les situations adverses décrites ci-dessus, le mieux est évidemment de tout faire pour qu'elles n'arrivent pas. Mais pas mal d'événements sont difficiles à contrôler. Une fois que le problème arrive, la meilleure solution est en général de trancher. Sacrifier. Tuer si possible la tâche qui déborde pour sauver les 99 autres.
Dans le contexte CLI , un exemple classique est le cron . Si vous planifiez l'exécution toutes les minutes d'une tâche qui se met soudainement à prendre 1min30, vous allez avoir plusieurs problèmes. Ces tâches vont s'accumuler (sans fin) donc 1/ consommer de plus en plus de RAM, 2/ se battre pour les mêmes ressources (CPU, IO) donc toutes ralentir et 3/ en général bugger de façon aléatoire, car non conçues pour être exécutées simultanément.
Les règles d'or du cron :
- évitez les jobs qui s'exécutent toutes les minutes, ce sont des champs de mine ;
- évitez de planifier des jobs au même instant en copiant/collant des lignes dans la crontab , rassemblez-les en un "méta-job" si possible ;
- évitez de déclarer plus de 5 règles de cron custom par serveur, sous peine d'être en incapacité de vérifier le point précédent ;
- empêchez la simultanéité des jobs, par ex. avec
flock -n /tmp/<nom-job> command args || echo "Lock prevented this job execution"; - et/ou gérez des files d'attentes (une solution maison chez nous est jobq - mais il faut alors surveiller et administrer les files).
Enfin dans le contexte CGI/FPM/Apache , il faut savoir dire non à coup de HTTP 503. Pour cela il faut limiter les files d'attente . Il y en a en général deux importantes dans le serveur HTTP / loadbalancer / cache qui s'insère entre votre utilisateur et votre application :
- Admission : très souvent la taille de la file d'attente est exprimée en temps, via un délai maximum. Par exemple le vaguement nommé timeout chez Apache. Pour le dimensionner, pensez à votre utilisateur : si vous pensez qu'il n'attendra pas plus de 10 secondes pour une réponse (et fermera son onglet ou ira voir ailleurs), alors réglez votre timeout sur 10s . En pratique il existe peu de raisons de dépasser 30 secondes.
- Backend : ici il s'agit de l'attente du serveur/proxy HTTP vis-à-vis de votre application. Si vous savez que 95% des réponses peuvent être obtenues en moins d'1 seconde, alors le timeout de cette file d'attente devrait être du même ordre de grandeur, probablement entre 3 et 5 secondes max. Chez Apache c'est le bien nommé ProxyTimeout
Corollaire : soignez le contenu de la page 503 renvoyée par votre serveur/proxy/cache HTTP, c'est toujours possible. Surveillez le taux de 503 que vous renvoyez, si vous êtes autour de 1% vous êtes au top (et vous remarquerez souvent que ces 1% sont de stupides bots faisant l'effet d'un fuzzer et découvrant les pires cas de votre application).
Règles de tuning PHP
Nous vous suggérons de lire ou relire notre article sur la configuration d'un Apache moderne si ce n'est déjà fait, nous éviterons ainsi des redites.
memory_limit
Voyons déjà ce que ce paramètre ne limite pas : il ne contrôle que la mémoire allouée par PHP pour des ressources PHP (types natifs, objets, etc.). Il ne contrôle pas en particulier l'usage de la mémoire de tous les modules tiers (XML, MySQL, GD/ImageMagic, etc.) qui s'interfacent directement avec malloc() .
C'est pour cette raison que nous conseillons par exemple de préférer invoquer les commandes ImageMagick via un appel system() : d'une part les statistiques d'utilisation mémoire de PHP seront plus fidèles, d'autre part il est nettement plus efficace pour un admin de pouvoir observer séparément l'exécution des commandes et leur consommation propre en CPU/RAM/IO (avec un outil tel que atop ).
Un des gros problèmes de memory_limit est son change mode PHP_INI_ALL : n'importe quelle partie du programme (et en partie d'une bibliothèque que vous ne soupçonniez pas) peut changer cette limite. En général on voit un jeu du chat et de la souris entre le programmeur d'une part qui 1/ ne sait pas quoi mettre comme valeur par défaut et 2/ adore invoquer ini_set('memory_limit', '4096m') au détour d'une fonction parce qu'il a 4 GB sur son laptop et que ça l'a débloqué une fois - et l'admin d'autre part qui sait quelle valeur choisir (par expérience et observation) et aimerait s'assurer qu'elle est honorée par les programmes PHP invoqués.
Le compromis que nous conseillons si ça finit en guerre de tranchées : autorisez UN appel à ini_set('memory_limit', '<grosse valeur>') au programmeur mais avec ces contraintes :
- c'est OK pour le CLI, mais cela doit être pris en compte dans le dimensionnement (ex: on prévoit jusqu'à 4 tâches cron simultanées avec chacune jusqu'à 2G d'utilisation mémoire : on provisionne 8G de consommation en pic); dans ce cas l'idéal est d'entériner cet accord dans php.ini et ne pas invoquer
ini_set(...); - pour CGI/FPM/apache, cela doit être dans une branche de code uniquement accessible à un administrateur de site ET rarement invoquée.
Chers développeurs, attention : un admin armé d'un grep bien aiguisé peut détecter vos abus en quelques secondes. Vérifiez à quel gage vous vous exposez...
max_execution_time
C'est de loin le paramètre le plus piégeux. La doc est peu claire, mais il s'agit de limiter le temps CPU et non le temps chronomètre . La valeur par défaut est donc assez affolante pour le contexte non-CLI : elle autorise n'importe quelle requête à consommer 30 secondes de la vie d'un coeur CPU. Si votre application fait du calcul à la demande, pourquoi pas, mais si c'est un blog cette valeur est insensée (votre budget serait plutôt de 1 à 3 secondes CPU max).
Notez que si parfois vous avez des requêtes longues à répondre mais qui consomment peu de ressources (le classique dump/export d'un backoffice qui est limité par la capacité de download de l'utilisateur), ce n'est souvent pas le paramètre qu'il faut changer . Allez plutôt voir du côté des serveurs HTTP/proxy/cache en amont qui ont tendance à limiter en temps les sessions, surtout si elles sont inactives (quand par ex. le premier octet met beaucoup de temps à sortir de votre application).
En relation avec notre conseil sur les proxies plus haut, il serait bien que chaque traitement de requête HTTP ne dépasse pas le temps de timeout "backend". Sinon la requête aura bien été abandonnée vu de l'utilisateur (qui recevra une 503) mais en fait elle continuera à s'exécuter et consommer des ressources pour envoyer sa réponse à /dev/null .
Il n'y a pas de solution prévue dans le langage PHP lui-même, mais pour certains SAPI cela est possible :
- FPM : le paramètre request_terminate_timeout peut servir à cet effet mais il est assez radical, il tue l'interpréteur au lieu de simplement interrompre le flux du programme; c'est mauvais pour les performances (même si le cache FPM est partagé) et pas forcément fiable pour vos données
- mod_fcgid : c'est le rôle du paramètre FcgidBusyTimeout ; les mêmes caveat que pour FPM/request_terminate_timeout s'appliquent
C'est hélas l'un des nombreux défauts que l'on déplore quand on compare les modèles d'exécution de PHP, qui sont résolus depuis longtemps dans les univers Ruby, Python, Perl, Node, etc.
max_input_time
C'est un paramètre qui contrôle le délai maximum des traitements qui ont lieu dans PHP avant que l'interpréteur lance votre programme. Les traitements sont indiqués comme "parsing des données GET et POST", c'est vague.
Intuitivement, on soupçonnerait que ça permet de limiter ce qui prend le plus de temps en entrée : la réception des uploads de fichiers. Après vérification par nos soins, que vous passiez par mod_fcgid ou FPM, les uploads de fichiers ne sont pas concernés par ce paramètre. Car ces derniers sont bufferisés en amont sur le disque, avant même que l'interpréteur PHP soit initialisé.
L'utilité de ce paramètre nous semble donc très douteuse. Tout au plus elle peut éventuellement protéger PHP contre des attaques algorithmiques sur les parseurs de variable (query string, corps de type multipart/form-data), c'est probablement pour cela que ce mécanisme a été pensé. Mais du coup il aurait été plus logique que 1/ son unité soit en temps CPU plutôt que temps chronomètre (l'implémentation utilise setitimer() ) et 2/ que la valeur par défaut soit de l'ordre de quelques secondes (par défaut elle hérite des 30s de max_execution_time ).
Notre recommandation : n'y touchez pas, gardez la valeur -1 par défaut.
default_socket_timeout
Dans la tradition de la documentation évasive de PHP, on ne sait pas de quel timeout il s'agit : celui de connection ? Celui d'inactivité ? Si vous avancez dans la doc - stream_set_timeout() - vous n'êtes pas plus avancés...
En plongeant dans les sources, on peut enfin trouver l'explication : il s'agit d'une valeur qui est utilisée dans une boucle poll() après chaque appel système de type open() , read() et write() . C'est donc une valeur assez intuitive pour le programmeur, chaque appel système a un budget temps. Mais c'est peu pratique pour l'admin, car du coup il est impossible de désigner un temps global maximal pour une session TCP, ou un délai d'inactivité - ce qui est en général nécessaire pour gérer efficacement les ressources système.
Par ailleurs ce paramètre default_socket_timeout ne concerne que quelques fonctions :
- socket_*
- fopen('http://...')
- streams PHP
Et donc ne concerne pas les modules tiers qui utilisent aussi des "sockets" sans passer par l'API de PHP : Curl, MySQL, etc.
Néammoins ceci peut être fort utile. Si dans votre application vous vous adressez à un service externe via HTTP, vous allez aligner vos performances et votre disponibilité sur ce service externe si vous ne prenez pas de précautions : le service externe rame, votre site rame; le service externe tombe, votre site tombe. Evidemment si ce service est une dépendance obligatoire (par ex. votre service d'authentification), vous n'avez pas le choix. Mais si c'est juste pour aller chercher la météo et l'afficher dans un coin, quel gâchis...
Si vous avez décidé plus haut que répondre au delà de 10 secondes d'attente n'était pas acceptable, alors ne dépassez 5 secondes pour ce paramètre. N'hésitez pas à baisser encore cette valeur et accepter un taux d'erreur, car en général ce problème est sujet à des phénomènes d'amplification : on utilise souvent plusieurs services externes, et les interconnections entre votre serveur et ces services vont avoir une probabilité nettement plus élevée d'avoir des incidents que si votre serveur fonctionnait de façon isolée.
Corollaire : des appels externes (API, etc.) vont parfois échouer, arrangez-vous pour que ce cas soit traité correctement. En général 90% du travail est dans l'UI et la façon de faire accepter un manque d'information (éventuellement ponctuel) auprès de l'utilisateur.
Conclusion
Merci d'avoir lu ce billet jusqu'au bout, nous sommes conscients qu'il est assez dense. Cependant ceci n'est qu'un petit extrait du savoir-faire nécessaire au ronronnement des applis webs. Par ailleurs, nous n'effleurons que le cas de PHP, il faudrait des romans fleuves pour continuer à couvrir Ruby/Rails, Python/Django, Node/whatever, etc. Ne parlons pas des bases de données plus ou moins relationnelles ...
Nous pensons donc qu'il est tout à fait légitime qu'un développeur PHP ne puisse pas connaître et maîtriser tous ces aspects, c'est pour cela qu'il y a des métiers comme infogéreur, SRE - appelez-le comme vous voulez. C'est en particulier l'une des expertises de Bearstech, confiez-nous vos sites, on les fera rouler comme des horloges !







