Dans l'article précédent, nous avons vu les principes sur lesquels le workflow devops de Bearstech repose (opensource, transparence, mesure de la fiabilité des applications). Dans cet article, nous allons vous présenter son fonctionnement et quelques cas pratiques qui peuvent s'appliquer aux différentes étapes du cycle de vie des projets informatiques.
Ne manquez aucune mise à jour !
Inscrivez-vous à notre newsletter pour recevoir des actualités exclusives, des conseils et des offres directement dans votre boîte mail.
Notre workflow
Notre but étant de viser la fiabilité des applications, nous avons conçu un environnement de travail sécurisé et transparent qui peut s'adapter à tous types de projets. Il respecte les bonnes pratiques d'un développement qui prend au sérieux les questions de sécurité et de performance applicatives.
Bearstech propose un workflow modulaire, qui n’impose que peu de règles prédéfinies, qui se paramètrent dans des fichiers, de manière transparente. Il effectue pour le développeur les opérations de préparation de l'environnement d'exploitation:
- provisionner un serveur
- paramétrer des services web
- générer des certificats pour authentifier l’application
- provisionner un service de BDD
- définir un système de cache ...
De plus, il apporte un environnement de travail complet, maintenu par Bearstech :
- pour versionner le code, créer des branches et des merge requests
- pour automatiser des tâches sur la CI selon les étapes de livraison du code : intégration, tests, recette, staging, production
- échanger avec mon équipe, suivre les sorties de tests, des déploiements, analyser la productivité ...
Les développeurs disposent ainsi d'une plateforme qui regroupe un ensemble d'outils qui leur permettent d'assembler les couches logicielles plus simplement, de valider l'intégration de leurs applications dans un contexte d'exploitation stable, tout en gardant le contrôle sur propres leurs environnements de travail.
Instancier l'application sur la CI
Le workflow devops de Bearstech est modulaire, il peut donc couvrir pas mal de cas d'usages pour les applications courantes. Les services à invoquer se paramètrent dans le fichier .gitlab-ci.yml des projets.
Dans le cas d'un scénario de workflow qui souhaite valider le bon fonctionnement d'une application par des tests d'intégration et des tests fonctionnels, il faudra spécifier à la CI les règles nécessaires pour instancier l'application de manière temporaire avant son déploiement vers les environnements de staging ou de production.
Fichiers requis
Dans ce cas, il sera souhaitable d'utiliser d'embarquer l'application dans des conteneurs. Le workflow aura besoin au moins de 3 fichiers pour fonctionner:
.gitlab-ci.ymlpour lister les actions à exécuter sur la CI. Dans le cas de notre scénario, il faudra au moins 2 étapes: le build de l'image Docker, et le déploiement.Dockerfilepour l'image de l'application et ses dépendances à embarquer.docker-compose.ymlpour lister les services utilisés par l'application.
Reverse proxy
Notre workflow met à disposition un reverse-proxy qui permet d'exposer publiquement et de manière sécurisée les conteneurs. Nous utilisons Traefik car il permet de gérer dynamiquement les configurations. Dans le workflow c'est lui qui dispatche les requêtes aux conteneurs.
Le workflow inclut les directives Docker pour lier Traefik à votre application. Traefik va écouter la socket Docker (docker.sock) pour ouvrir les connexions sur le réseau privé créé par Docker, et permet ensuite de s'y connecter en http pour intéragir avec le ou les conteneurs.
En production, Traefik ne tourne pas dans un conteneur, mais il écoute la socket docker.sock, il intercepte les événements de création de conteneurs, il les inspecte, récupère l'ip du réseau et expose l'application proprement: le workflow interdit d'exposer publiquement les ports des applications qui tournent sous Docker, seul le port du reverse-proxy Traefik est public (80 et 443).
Réaliser les tests dans la CI
Tests unitaires
Grâce à la CI et à Docker, il est désormais possible d'automatiser les tests unitaires qui doivent être réalisés avant le build de l'image de l'application. Dans la documentation du workflow, nous avons décrit une procédure pour réaliser des tests unitaires sur une application écrite en Python en utilisant l'utilitaire pytest.
Tests fonctionnels
Une fois l'application et le reverse-proxy instanciés sur la CI, il est ensuite possible de lancer des tests directement sur l'infrastructure temporaire qui, dans notre workflow, tourne dans un conteneur LXC afin de bien sécuriser l'environnement.
Nous avons écrit pas mal d'article sur le sujet des tests fonctionnels qui permettent de valider la pile logicielle d'une applicaton ( Tests fonctionnels avec browserless et Cas d'usage pour des tests fonctionnels avancés ), aussi nous n'allons pas nous étendre à nouveau sur les outils qui permettent d'émuler un navigateur headless afin d'obtenir dans la CI une sortie propre pour le résultat des tests.
Infrastructure cloud - Profitez d'un support dédié
Sécurité, performance, sérénité : confiez vos serveurs à des spécialistes.
Un déploiement flexible
Les contraintes ne sont pas les mêmes en production et en staging, c'est pourquoi notre workflow s'adapte aux besoins de flexibilité pour les environnements de recette et aux besoins de stabilité et de performance pour les environnements de production. Par son aspect modulaire, notre système de déploiement prend en compte les besoins de flexibilité pour les phases de développement et de recette, pour ensuite couvrir les besoins de stabilité en préprod et en production. Pour plus de détails sur ces deux aspects du déploiement, nous vous invitons à consulter la documentation de notre workflow pour les principes de déploiement d' application hébergées en natif avec son quick-start , et ceux pour les applications conteneurisées avec son quick-start .
Ce déploiement modulaire permet de couvir les besoins d'organisation des projets informatiques actuels. Voici quelques exemples pratiques de déploiement qui démontrent la souplesse du workflow:
L'agilité
L'app-review
Cette méthode de déploiement permet de comparer plusieurs versions de l'application simultanément. Cette méthode est particulièrement utile en développement pour valider telle ou telle fonctionnalité. Couplée à Docker, notre workflow permet de déployer des conteneurs en fonction des branches de votre projet, et configure automatiquement un point d'accès HTTP qui reprend le nom de la branche dans l'url.
Cela permet de publier l’application sur une url temporaire, à côté des url “officielles” déployées sur les environnements (staging et production). Le workflow devops de Bearstech implémente cette technique au moyen du reverse-proxy en déployant les conteneurs dans un environnement spécifique à la branche de commit (voir notre documentation technique à ce sujet).
Le Déploiement "Blue/green"
Cette méthode de publication permet à un nombre limité d'utilisateurs d'accéder à certaines fonctionnalités, avant de les diffuser à tous les autres.
Notre workflow permet lier la branche du dépôt qui déclenche le déploiement et la machine cible (target). Ainsi, les fonctionnalités qui sont destinées à être validées dans un environnement spécifique peuvent être livrées au moment voulu.
Attention, ce mode de déploiement doit être adjoint à un loadbalancer qui s'occupe de répartir le trafic entre les différents environnements. Le paramétrage du loadbalancer est une opération distincte du workflow (voir exemple un exemple de paramétrage chez OVH pour une répartition du trafic en fonction des ports).
Le rollback
En cas de dysfonctionnement de l'application en production qui n'a pas pu être détecté en amont (typiquement lors la mise à jour de modules tiers), pouvoir revenir à une version précédente de l'application est une opération que le système de déploiement permet de simplifier considérablement. En effet, que ce soit dans le cadre d'un déploiement natif ou avec des conteneurs, chaque déploiement a lieu en identifiant l'ID d'un commit:
- le déploiement natif effectue un
git pullsur l'id de commit qui a déclenché la pipeline, et cela permet de rejouer en cas de besoin une pipeline qui utilisera une version précédente du code de l'application. - le déploiement de conteneurs utilisera un principe similaire, en permettant de rejouer le build d'une image Docker qui utilise une version précédente du code de l'application.
A noter qu'en ce qui concerne les données stockées en BDD ou leurs structures, il faudra utiliser une procédure de restauration qui s'appuiera sur un backup (dump) auquel on pourra adjoindre une reconstruction de sa structure, si ces modifications sont également versionnées dans le code du projet.
Infogérance
Une fois la gestion des dépendances fiabilisée grâce à la CI et aux bonnes pratiques du workflow, la continuité passe par l'infogérance des services en exploitation. L'infogérance des dépendances système et applicative consiste à automatiser leurs mises à jour de sécurité, et à disposer d'un monitoring pour déclencher des alertes. Notre workflow intègre la mise à disposition des sondes de surveillance nécessaires à la mise en oeuvre d'un monitoring efficace pour les services exploités par l'application.
Nous mettons à la disposition de nos clients une interface web dédiée qui leur permet d'accéder à une synthèse de leurs environnements.
L'infogérance s'organise différemment selon le mode de déploiement utilisé:
Infogérance pour les services natifs
L'infogérance se fait de manière classique: les paquets bénéficient des mises à jour de sécurité selon la version stable de la distribution exploitée en production. Les métriques sont récoltées en provenance des ressources du système (CPU, RAM, Réseau, Disque ...) et des services instanciés (serveurs web, SGBD, systèmes de cache ...) Les mises à jour de sécurité et la surveillance des métriques se fait au niveau système. C'est à dire que l'automatisation des procédures de mise à jour et de récolte des mesures intervient dans le cadre des procédures de maintenance définies par la version de Debian utilisée. Vous n'avez donc rien à faire pour garantir que votre application bénéficie d'un environnement système stable et sécurisé. Si vos applications ont besoin de librairies spécifiques (Imagick, ClamAV, Memcached, Composer ...) nous pouvons les installer à la demande.
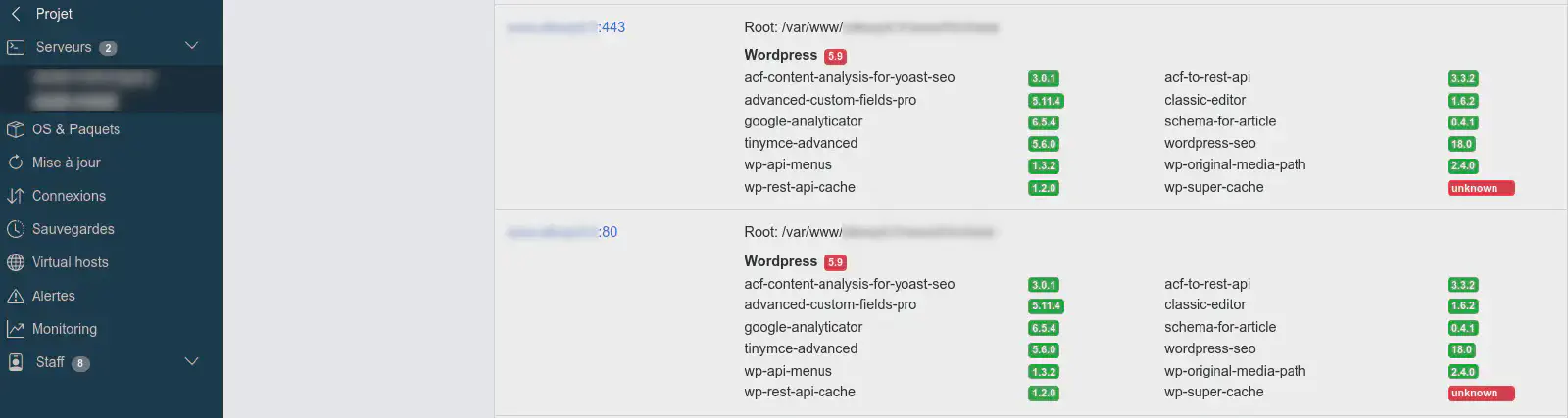
Synthèse visible dans l'interface web de l'infogérance Bearstech pour les dépendances applicatives d'une application Wordpress exploitée nativement: la version du wordpress core et des modules qui l’accompagnent est analysée afin d’indiquer si une version supérieure est disponible (dans ce cas le badge de version s’affiche en rouge).
Infogérance des services conteneurisés
Les applications conteneurisées ont une pile système indépendante du système hôte. Bearstech ne peut donc pas intervenir directement sur cette partie, car le choix du système sur lequel repose l'application devient la responsabilité des développeurs. L'infogérance s'applique donc à 2 niveaux : sur l'environnement d'exploitation (maintenance de l'OS de la machine hôte), et sur l'image Docker de base qui sert à builder l'application. Bearstech maintient à jour les images pour les distributions Debian Buster et Bullseye, et selon l'applicatif. A l'heure actuelle, nous maintenons les images Docker pour PHP (de la version 7.0 à 8.2), NodeJS (versions 16, 18 et 20), Ruby (version 3), et Nginx (latest). En production, les métriques de chaque conteneur sont récoltées au niveau de leur consommation CPU, RAM, Réseau et Disque.
Afin de garantir une sécurité optimale pour les images Docker, nous maintenons des images applicatives pour les projets courants. Ces images reposent sur les procédures de mises à jour de sécurité des releases Debian. Nous encourageons donc fortement les développeurs à utiliser nos images afin de builder leurs applications.
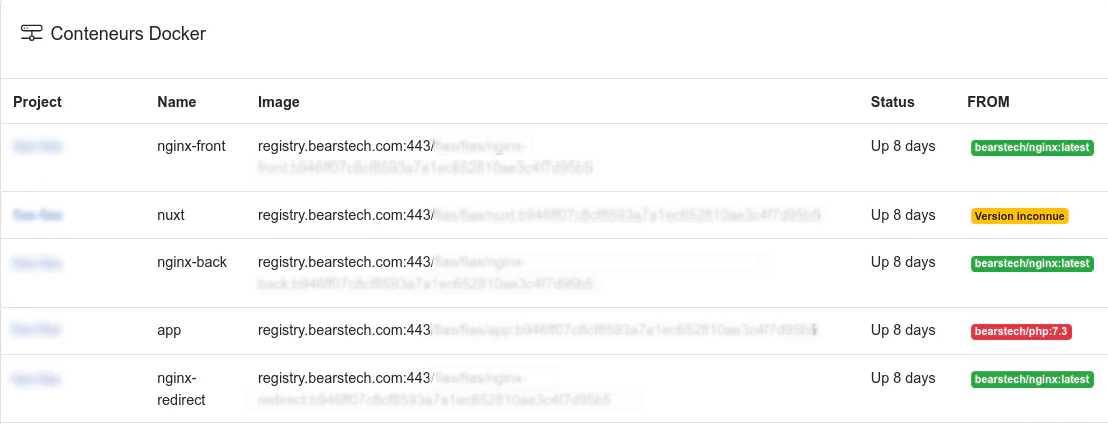
Synthèse visible dans l'interface web de l'infogérance Bearstech pour les conteneurs instanciés sur un serveur, avec l'état de mise à jour de l'image de base: La colonne “FROM” à droite indique le statut de l’image Docker de base (le “from” du Dockerfile) à partir de laquelle l’image de l’application est construite:
- vert : l’image de base est à jour,
- rouge : l’image de base est plus récente que celle utilisée par l’application. L’image de l’application doit être rebuildée et redéployée pour bénéficier des dernières mises à jour de sécurité
- jaune : le statut de l’image de base est inconnu.
Conclusion
Le workflow devops que propose Bearstech n'est pas seulement un ensemble d'outils qui permettent de mettre en oeuvre les bonnes pratiques (sécuriser, tester, améliorer ...) pour intégrer et déployer les applications. C'est aussi un cadre logiciel générique qui repose sur des services opensource qui ont fait leur preuve (Gitlab, Grafana, Telegraf, Ansible ...) et que Bearstech maintient pour vous afin de vous garantir la transparence des processus, et la robustesse d'une plateforme qui vous accompagnera tout au long du cycle de vie de vos applications, et vous fera gagner en rentabilité sur vos projets. Plus qu'un service, c'est l'expérience de 18 ans d'expertises dans l'infogérance des applications sur le web qui vous sont transmises avec ce workflow.
Vous souhaitez en savoir plus ?
Découvrez notre workflow DevOps et échangeons sur vos enjeux technologiques.